Hello community,
we have upgraded a big Plone site from 4 to 5 (which eventually will be upgrade to 6). We have noticed a big performance penalty during that upgrade (average response hiked from ~1s to 3.5s).
Upon inspecting with py-spy on a running production instance, we gathered that 40-45% of the time is spent in Products/ZCatalog/Catalog.py, namely:
rs = intersection(rs, index_rs)
That part should be responsible for the intersection of the current result set with the one of the index. Has something dramatically changed in Products.ZCatalog (from 2.13.29 to 5.4) that explains such behavior like changes in the query plan?
Do you have experienced similar issues and what did you do?
Can you show more of what you measured with py-spy? BTree intersection is implemented in C and quite fast, so I would guess that the slow part here might actually be loading uncached BTree buckets from the ZODB. Is it faster if you do the same request against the same instance a second time?
There are some portal_catalog tabs in the ZMI which let you see which indexes were involved in slow queries. Does this give any insight into which queries are slow and whether or not the query plan is sensible?
Precomplied eggs vs compiled on the server? Maybe some optimization has been lost?
I have looked into that. The *.pyc files seems to be present and up-to-date.
Can you show more of what you measured with py-spy? BTree intersection is implemented in C and quite fast, so I would guess that the slow part here might actually be loading uncached BTree buckets from the ZODB. Is it faster if you do the same request against the same instance a second time?
Sure, I recorded the zeoclient process for 5 minutes and exported the result format for speedscope:
py-spy record -p 12345 -o var/profile.svg -f speedscope -d 300
The result is as follows (sent full-report via PM):
When I run a dedicated zeoclient in debug mode and enter the catalog query manually, the first query takes a bit but the subsequent one is instantaneous. So caching works I assume. We also have a dedicated mount point for the portal_catalog to control the cache settings (experimented with very generous limits with cache-size=0 and cache-size-bytes=8GB, but no improvements).
The hint with the catalog tab in ZMI is very good. There are also cache hits shown, but the mean duration is still quite high. I will investigate further in that direction. One question: On the right hand side, entries with "index#intersection" correspond to the intersection operation with that index?
Due to the long requests, we have already noticed on the WSGI side, that requests are piling up and we get warnings regarding the task queue. As a quick measure, we have increased the Varnish cache time to have fewer requests on the actual zeoclients. We have already a pretty good purge policy, so there should not be a big downside.
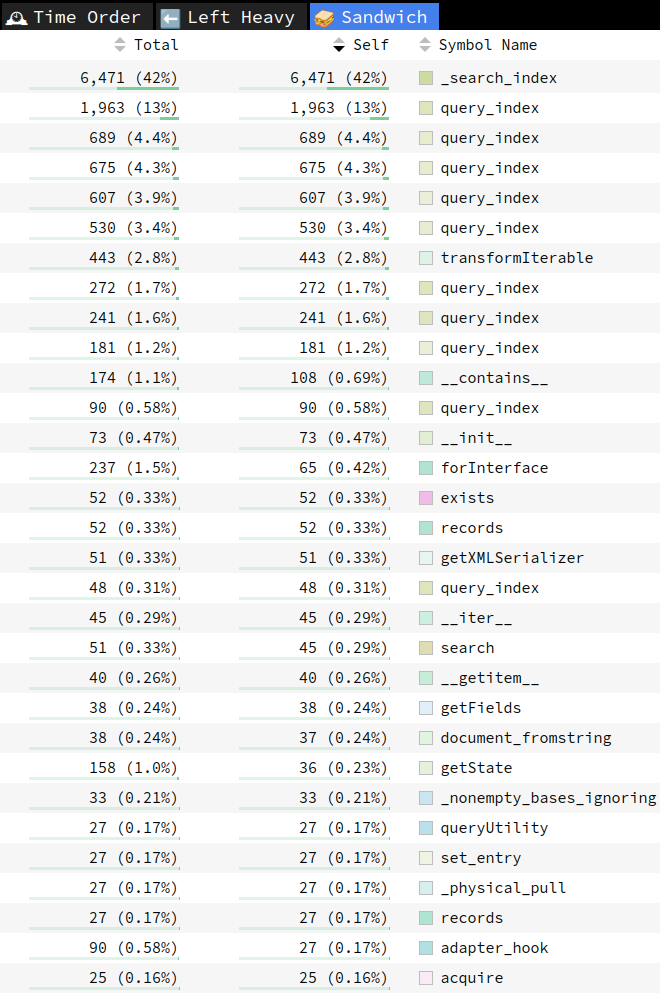
Hi @pgg ,
In your ZCatalog screenshot, I recognized something I had seen before.
In the plans I see allowedRolesAnUsers as the first index to be used. This is quite underperforming, because for example in your first query the index that should be first, in my opinion should be path.
try downgrading to ZCatalog 6.2, thus removing the optimizations to the catalog, to rule out that in your case the optimizations actually worsen performance for some reason (since you noticed a worsening with the upgrade)
try to see if your query plans vary all the time (putting a log here Products.ZCatalog.plan.CatalogPlan.stop)
If this is the problem it would be interesting to figure out why and how to improve it
Thanks for the input so far. I have spent the time investigating, that's why my answer took awhile.
@mamico: In my local setup I installed both ZCatalog 6.4 and ZCatalog 6.2 on our Plone 5 (which is possible, when I reinstate the removed import-aliases). I'm afraid, that the potential improvements were not great enough to properly determine a benefit. Maybe further inspections on a dedicated machine (without the random noise of other applications) may yield more reliable results.
What has helped more apparent was clearing and rebuilding the catalog. That improved the initial catalog queries computation by 25%. The benefit dimishes after the catalog begins caching. While clear&rebuild helped, it now comes to the next problem: How to rebuild the catalog on a running Plone site, favorably without a downtime?
Since we made no further meaningful progress for the catalog. We also looking into other parts:
removing unecessary Viewlets, that reappeared in other ViewletManagers), that weren't event shown in our theme
Inspecing Diazo's slow performance, but we found out, that Diazo's transformed rules are cached thread-wise. The previous implementation in plone.app.theming cached it for all threads altogether. This new way works as supposed, when all threads are warmed up.
Fixing logical bugs in our code, that waked up too many objects.
Mainly to prevent the increasing memory consumption: Various different setups with our thread-count, allotted memory etc.
We have also started monitoring our performance with Sentry, but certainly not to the fullest extend. This would require lots of monkey-patches for our points of interest.
Rebuilding the catalog without downtime is challenging. In theory it might be possible to add a new catalog, arrange for indexing operations to be dispatched to it as well as to portal_catalog, then run a script to index all content, and finally replace portal_catalog with the new one. But this would slow down indexing during the period when indexing is happening in 2 catalogs, and I haven't actually tried it.
If the first queries after starting Zope are slow because a bad query plan is used, it might help to copy the query plan after the instance has been running for a little while, and load this stored plan into the catalog during startup.
I have seen in another site that DateRangeIndex can be quite slow on the first queries after startup if the index stores many different date values, because querying the index requires loading a separate BTree for each value. I was able to optimize this for the effectiveRange index by writing a custom indexer which replaces effective dates in the past with None. This works because Plone only queries the current date in the effectiveRange index, and never dates in the past. This reduced the number of values stored in the index a lot, and made initial (uncached) queries much faster. I don't know if this is the same problem you have, though.
We have about 950K objects in the catalog. We also use raptus.multilanguagefields, that introduce some patches to introduce language-aware indexes and metadata fields. While upgrading from 4 and 5 the changes in Products.PluginIndexes were incorporated accordingly and I have not observed anything problematic in my point of view.
I also thought about building a second catalog in-place, but I was not sure, if anyone has attempted this before. But I will take a look into the catalogoptimize.py script. Thanks!
I heard about saving/loading the query plan, but I read in some message boards, that it might not be necessary or worth the trouble anymore. But in theory it definitely should help us, right after restarting our instances.
That custom indexer for DateRangeIndex sounds interesting, since of course the majority of our dates lie in the past. As a side note, I have noticed in Zope's Debug Information panel, that there many referenced DateTime objects (4.6M). I'm not sure, if this normal or due a misconfiguration?
Another phenomenon is, that in ZMI in portal_catalog the "Catalog" tab loads excruciatingly long, whereas it Plone 4 after like a minute or two (second request is cached/fast again).
I always disliked the "effective range" thing in Plone. I use a custom add-on similar to collective.autopublishing in order to depend only on the workflow state (private vs published).
Then I grant Access inactive portal content to all users, which prevents the effectiveRange being used in all queries, as the code linked above shows.
We're having a problem with a large catalog. Anonymous queries are taking a very long time. Queries with authenticated users are fast. After some debugging, we discovered that the difference is that, for anonymous users, the effectiveRange index is added to the query. Queries using this index are very slow, and the catalog plan is placing this index in the first positions most of the time, but it's still very slow.
What we did to work around the problem was to "ignore" the Catalog plan. We returned None here:
This made the queries return faster for anonymous users.
When Zope starts, the first query places the indexes in an order like this:
(someIndex, effectiveRange)
Since Zope has just started, due to lack of caching, connection creation, etc., the search in someIndex is slow. The search in effectiveRange is faster because the results are already filtered by someIndex, and there is less connection overload. So the plan considers that the search in effectiveRange is faster and puts it first for subsequent queries. But effectiveRange is not faster. The fact that Zope has just started means that, only under this condition, someIndex is slower, but in reality it is much faster. When effectiveRange is the first index, the searches are much slower, even with some caching. This may not be so noticeable in small and medium-sized catalogs, but it is quite noticeable in large catalogs. Until the system recognizes this, several requests are made before the index positions are swapped.
We implemented a patch to always place effectiveRange in the last position, and the performance improved significantly. Can we do this in Plone?
@jensens That would be interesting. The first requests are "polluted" in terms of timing. But even so, the initial sorting of the indexes would have to have some intelligence. I think today it's done alphabetically.