tl;dr: Long tags with high unicode codepoints are breaking. This bug is blocking our release of plone5
I think I have a bug bothering me. It gets aggravated on 'long terms' used in the Dublin Core Tags field, aka 'subject'. If the tag gets too long it gets mangled and an equals '=' is added.
To aggravate, edit an object (that has the Dublin Core behavior enabled), go to the
categorization tab, and insert this:
"this is a really really long, I mean really long tag that is over 72 bytes long"
and save.
Go back to edit, visit the page, and you will see and '=' appear:
"this is a really really long, I mean really long tag that is over 72 bytes =long"
Before you answer
'this is a crazy edge case and you shouldn't have tags that long'
consider our high unicode users.
We have a lao site with these keywords:
('chinareach', 'ຊາວບ້ານໃນ', 'ເມືອງວັງວຽງ', 'ບໍ່ຍອມເສັຍ', 'ດິນນາ', 'ບໍຣິສັດຈີນ')
and this is what gets displayed:
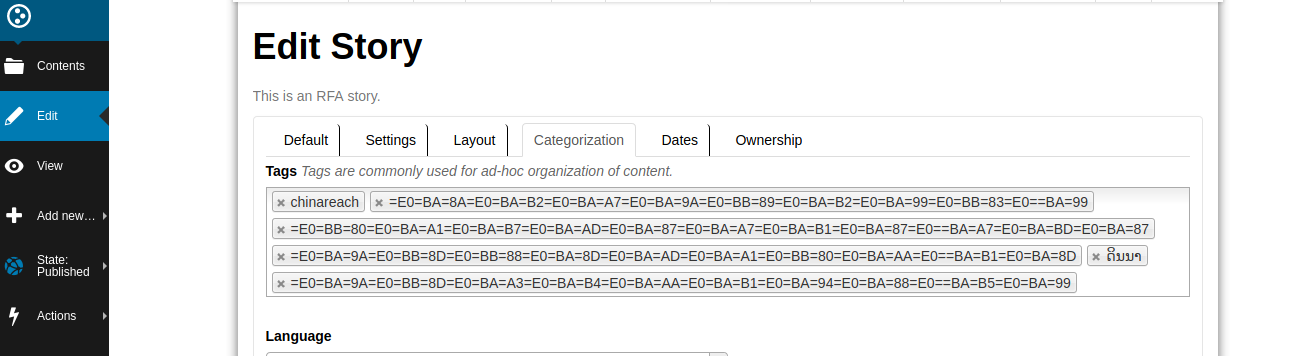
The keywords that are over 72 byes long get affected.
There are 3 utf-8 bytes representing each lao character, which turn into 9 ascii-encoded bytes (including the =) multuplied by 9 unincode characters > 72 bytes.
So, you are limited to 72 bytes of utf8 encoded string, which is not cutting it for Chinese, Lao, Burmese and other eastern languages.
Inspecting the object from debug shows the object itself is healthy:
>>> story.subject
('chinareach', 'ຊາວບ້ານໃນ', 'ເມືອງວັງວຽງ', 'ບໍ່ຍອມເສັຍ', 'ດິນນາ', 'ບໍຣິສັດຈີນ')
>>> story.subject[1]
'ຊາວບ້ານໃນ'
>>> story.subject[1].encode('utf8')
b'\xe0\xba\x8a\xe0\xba\xb2\xe0\xba\xa7\xe0\xba\x9a\xe0\xbb\x89\xe0\xba\xb2\xe0\xba\x99\xe0\xbb\x83\xe0\xba\x99'
>>> story.subject[1].encode('unicode_escape')
b'\\u0e8a\\u0eb2\\u0ea7\\u0e9a\\u0ec9\\u0eb2\\u0e99\\u0ec3\\u0e99'
What makes it worse is that if you save from here, you alter the tags. Deleting 'ຊາວບ້ານໃນ' and replacing it with =E0=BA=8A=E0=BA=B2...
Even worse, another save will encode the = and change it again to =3DE0=3DBA=3D8A..., and additional saves will prepend every byte with 3D causing an encoding disaster until you have =3D3D3D3D3DE0...
I've been debugging for about 6 hours now and need some help. The object has the correct value, the widget will ask for the vocabulary for the field and then ask the vocabulary for SimpleTerms with these values and then use the SimpleTerm 'token'- that's where the error seems to be - on the SimpleTerm token.
I have a theory that somewhere this SimpleTerm is being created with a token, and that token creation is being a bit mean to my unicode tags. SimpleTerm itself doesn't seem to be guilty, but some factory using it.
Any clues would be appreciated.

