you don't need to be one, but the issue you're having must be addressed by someone with experience deploying Plone sites.
you can find the size of your catalog by running an instance in debug mode (running something like bin/instance debug) and running the following commands:
>>> from zope.component.hooks import setSite
>>> site = app['Plone']
>>> setSite(site)
>>> len(site.portal_catalog())
72924
replace 'Plone' with your site id in case is different; as you can see there are 72.924 objects in the catalog of this site.
I have no idea how to get the average object size; that's a good question that must be addressed by someone else; I tried using the _p_estimated_size attribute of the objects but that gave me a value lower than I expected: 1.592.
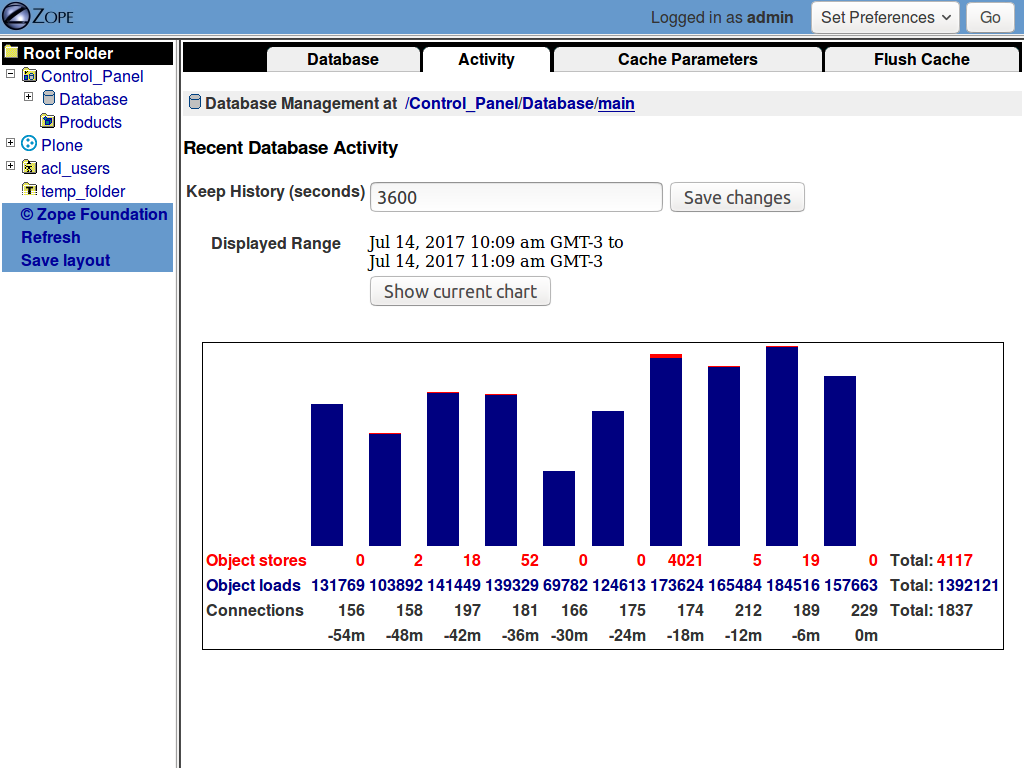
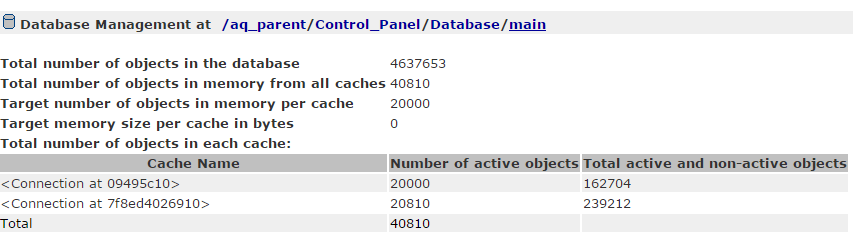
you can see the database activity on an instance by accessing the ZMI, and then selecting Control_Panel -> Database -> main -> Activity.
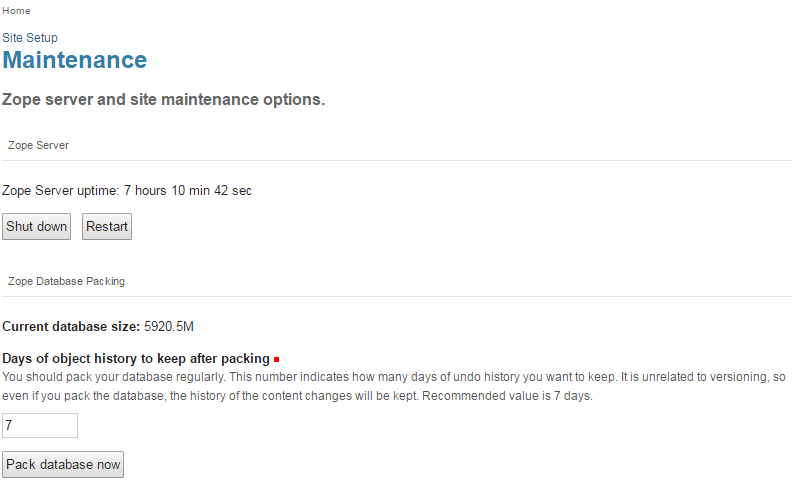
BTW, your Data.fs file is huge and you may need to compact the database. if after running that process you still see a file this big, then your objects are also huge and that may explain why the instances are consuming such amount of memory.
I still don't see the need of having 8 instances in your case; how many people is accessing your site? I have a site with 8 instances, but it has more than 4 million page view a month, and most of the backend traffic is caused by crawlers.
FYI, after I posted the statistics on the first server I noticed that something was really wrong with that site: 1.392.121 object loads in just one hour was not what I was expecting.
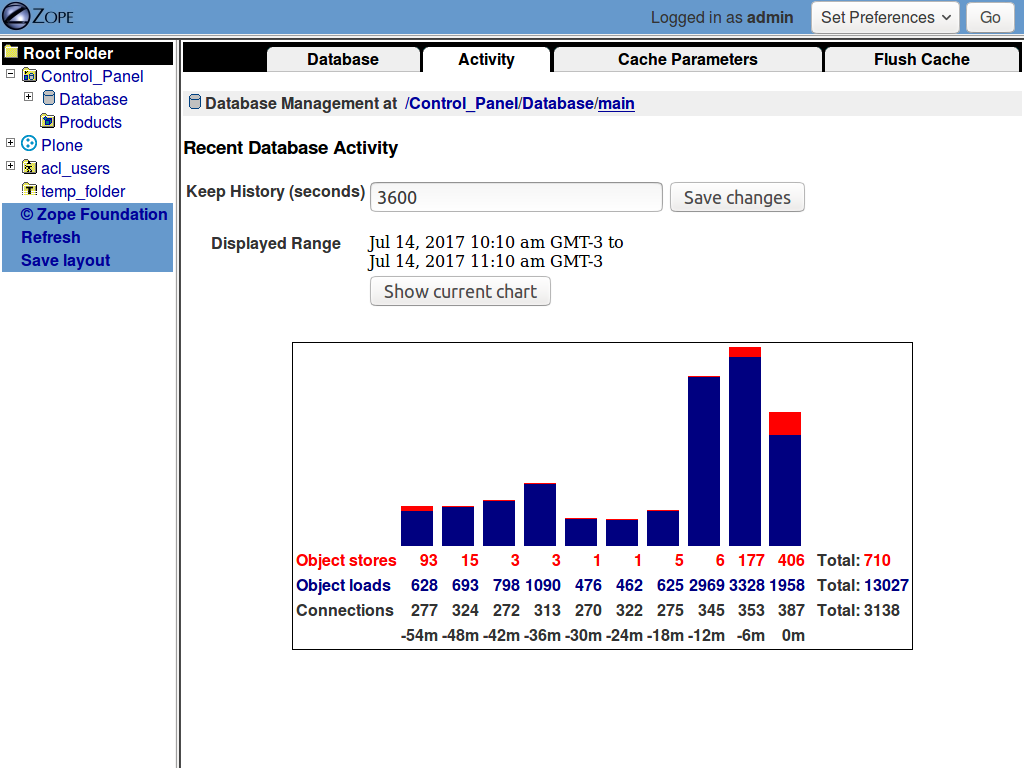
I plunged into the nginx logs and I discovered a lot of suspicious activity there from strange crawlers that I interpreted as a DoS attack.
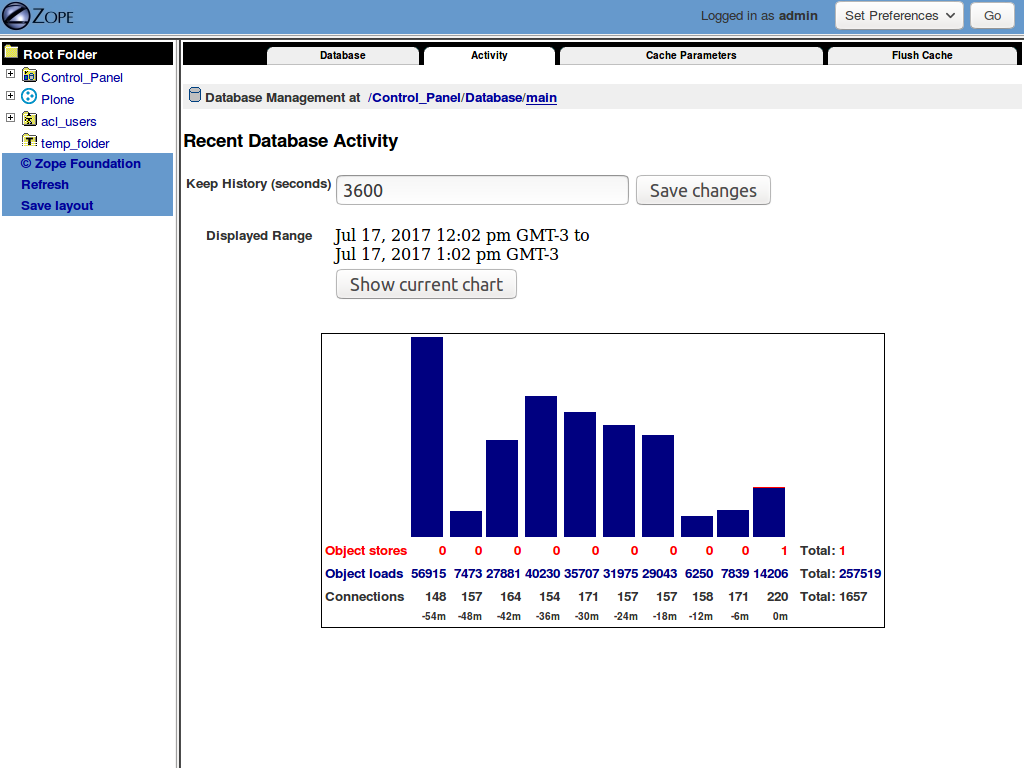
I blocked those crawlers and after that this is a more "normal" behavior:
now you can see "only" 257.519 object loads, which is still high, but 5 times smaller; I need to dig deeper.