Since we installed ZEO a coulpe of week ago and moved our site that has the highest request rate there, we have a good performance regarding response times, but we have a big problem in terms of memory consumption by the ZEO Clients.
In less than 24 hours they grow up to the maximum of the avilale memory+swap space and crash, so that our nightly automatic restart is not sufficient enough.
We started with 3 clients and 10 GB memory. In meantime we have got 12 GB Memory, but still the same problem.
Even after I have changed the Apache loadbalancer, so that only 2 of the clients get user requests, those two clients increase in memory consumption permanently.
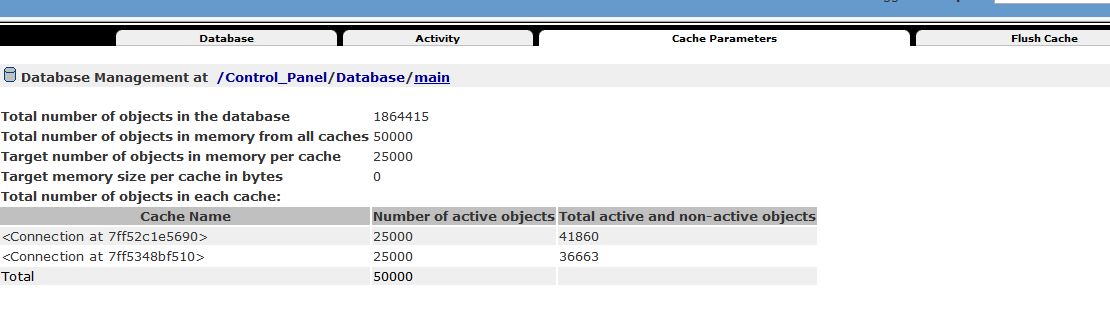
We have reduced the DB Cache to 25000 per thread, we have switched-off the PLONE Caching and we have played with differnet sizes for the cache-size in the section in zope.conf of the clients. Still the same problem.
We run Plone 5.0.10 (5020)
zope.conf for each client:
<zodb_db main>
# Main database
cache-size 25000
Blob-enabled ZEOStorage database
<zeoclient>
read-only false
read-only-fallback false
blob-dir /home/users/mlpd/Plone_rfnews_zeo/zeocluster/var/blobstorage
shared-blob-dir on
server 127.0.0.1:8080
storage 1
name zeostorage
var /home/users/mlpd/Plone_rfnews_zeo/zeocluster/parts/client3/var
cache-size 200MB
</zeoclient>
mount-point /
</zodb_db>
Whatever I found in the docs of issues listing did not help me.
It is not the ZEO server that has problems, but it are the Clients that have this memory problem.
Is there a memory leak in the ZEO Clients code? I could not yet find anything about that.
What I do not really unterstand from the Docs:
https://zope.readthedocs.io/en/latest/zopebook/ZEO.html says:
"ZEO servers do not have any in-memory cache for frequently or recently accessed items."
But it also says about the cache for ZEO Clients: "This cache keeps frequently accessed objects in memory on the ZEO client."
Does this cache influence memory consumption or - as I understood untill now - only disc space usage?
Anyway, different Values for its size did not alter our problem.
Any help would be much appreciated.