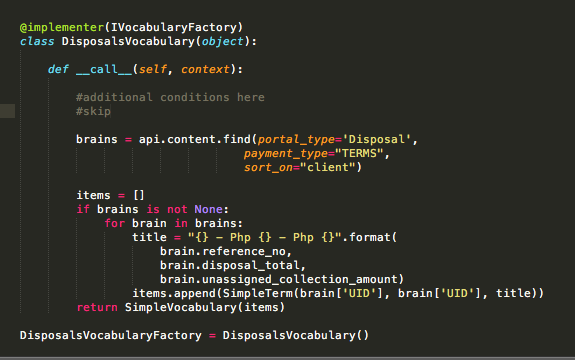
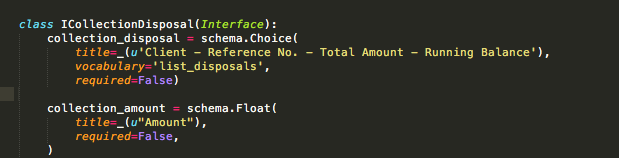
I am using DataGridFieldFactory with a choice field that uses a dynamic vocabulary (IVocabularyFactory). All seems to work fine. I am able to call the vocabulary and able to add the content.
But Datagrid calls the vocabulary every second, and calls again if you click the + button of the datagrid to add a new row. 2 initial calls for page load, then calls it infinitely or at least (20 calls ). This makes my add content page to load slowly, and adding a content would take minutessssss.
Maybe you could take a look at how it's done on existing add-ons ? I remember having looked at the code from collective.glossary and noticing the following;
from plone.memoize import ram
(...)
def _catalog_counter_cachekey(method, self):
"""Return a cachekey based on catalog updates."""
catalog = api.portal.get_tool('portal_catalog')
return str(catalog.getCounter())
(..)
class GlossaryView(BrowserView):
"""Default view of Glossary type"""
def __init__(self, context, request):
self.context = context
self.request = request
@ram.cache(_catalog_counter_cachekey)
def get_entries(self):
"""Get glossary entries and keep them in the desired format"""
catalog = api.portal.get_tool('portal_catalog')
path = '/'.join(self.context.getPhysicalPath())
query = dict(portal_type='Term', path={'query': path, 'depth': 1})
the catalog search is cached. Maybe you could take some inspiration from that ? full code at github
If you have success with this approach, be kind enough to post a report, I'll appreciate it (I have never used this technique and I am interested to know how much can be won with it)
Also it never hurts to have some caching on your site but I don't know if it applies in your case.
Apologies for reviving this old thread, but I'm trying to solve the same issue @milktea_plone was having. This page shows up in search results, so it may be useful to continue here.
The example from collective.glossary may not be optimal, see
Using the HTTP Request example provided in the Annotations documentation, I was able to substantially (50% or more) bring down page load times for content types which have Datagrid fields.
Example below is for a product which may be available in up 50 color variations and 5 package sizes. The datagrid may then be filled with attributes such as a suggested retail price, ean etc. for each color/size combination which is available for this product.
Colors and sizes may have been stored in the actual product or in a default "master".
@provider(IVocabularyFactory)
def ArticlesVocabulary(context):
request = getRequest()
key = "cache-%s" % context.getId()
# we could also set the annotation on the context
# object itself when it is saved
cache = IAnnotations(request)
data = cache.get(key, None)
if not data:
data = _ArticlesVocabulary(context)
cache[key] = data
return data
def _ArticlesVocabulary(context):
terms = []
p_catalog = getToolByName(context, 'portal_catalog')
package_size_vocabulary_factory = getUtility(IVocabularyFactory, 'mdb_theme.PackageSize')
package_size_vocabulary = package_size_vocabulary_factory(context)
color_brains = get_color_brains_for_product(context)
available_colors = get_ordered_colors( context
, color_brains
, color_type_list = u'default_color_names'
, color_type_mode = None
, priority_color_names = None
, )
""" Available packaging sizes for this product
a set with one or more members
e.g. set([u'l002500', u'x999999', u'l000250', u'l000750', u'l010000'])
"""
available_package_sizes = getattr(context, 'gebinde_grossen', None)
if not available_package_sizes:
# query the MDB if no custom package sizes
mdb_path = context.mdb_verweis.to_path
mdb_result = p_catalog.searchResults(path={'query':mdb_path, 'depth':0 })[0]
available_package_sizes = mdb_result.gebinde_grossen
for color in available_colors:
if available_package_sizes:
for p_size in sorted(available_package_sizes):
# Returns SimpleTerm object by value look-up
# Exclude "Grossere Mengen" value
if p_size != u'x999999':
p_term = package_size_vocabulary.getTermByToken(p_size)
s_token = p_term.token
s_value = p_term.value
s_title = p_term.title
t_value = '%s_%s' % (color['color_id'], s_value)
t_token = t_value
t_title = '%s - %s' % (color['color_title'], s_title)
terms.append(SimpleTerm(value=t_value, token=t_token, title=t_title))
else:
terms.append(SimpleTerm(value=color['color_id'], token=color['color_id'], title=color['color_title']))
return SimpleVocabulary(terms)
 ). This makes my add content page to load slowly, and adding a content would take minutessssss.
). This makes my add content page to load slowly, and adding a content would take minutessssss.