I know collective.googleanalytics tries to track clicks of pdf links but this is not really accurate enough as the file has to end in .pdf and direct links from search engines don't get included.
We would be very interested if anyone has a plugin that talks to google analytics server-side to track non-html requests.
BTW, we do currently goaccess and merge206 to try to track downloads via log files but it has its own issues.
We have a similar usecase - not with downloads but with tracking a particular views that msut be logged with user name, timestamp, parameters...we use my zopyx.plone.persistentlogger for this case and some small script for performing a search across related content objects and post-processing the collected information for further display purposes.
ideally a way that gives us a pretty report that the end user can interact with to get the stats they need without us having to do anything. Hence the the interest in a google analytics solution.
I know that the issue seems to be related to things loaded via ajax, this kind of tracking would need event based tracking. I'm probably telling you stuff you know already but... (for the sake of other readers) event based tracking, unlike page based tracking can be used to track clicks or even hovers and the whole thing can be customised using javascript.
It can be done with Google Analytics by itself but ideally you'll want to use Google Tagmanager.
You could do it without a plone add-on BUT it might be nice to integrate tagmanager support into collective.googleanalytics.
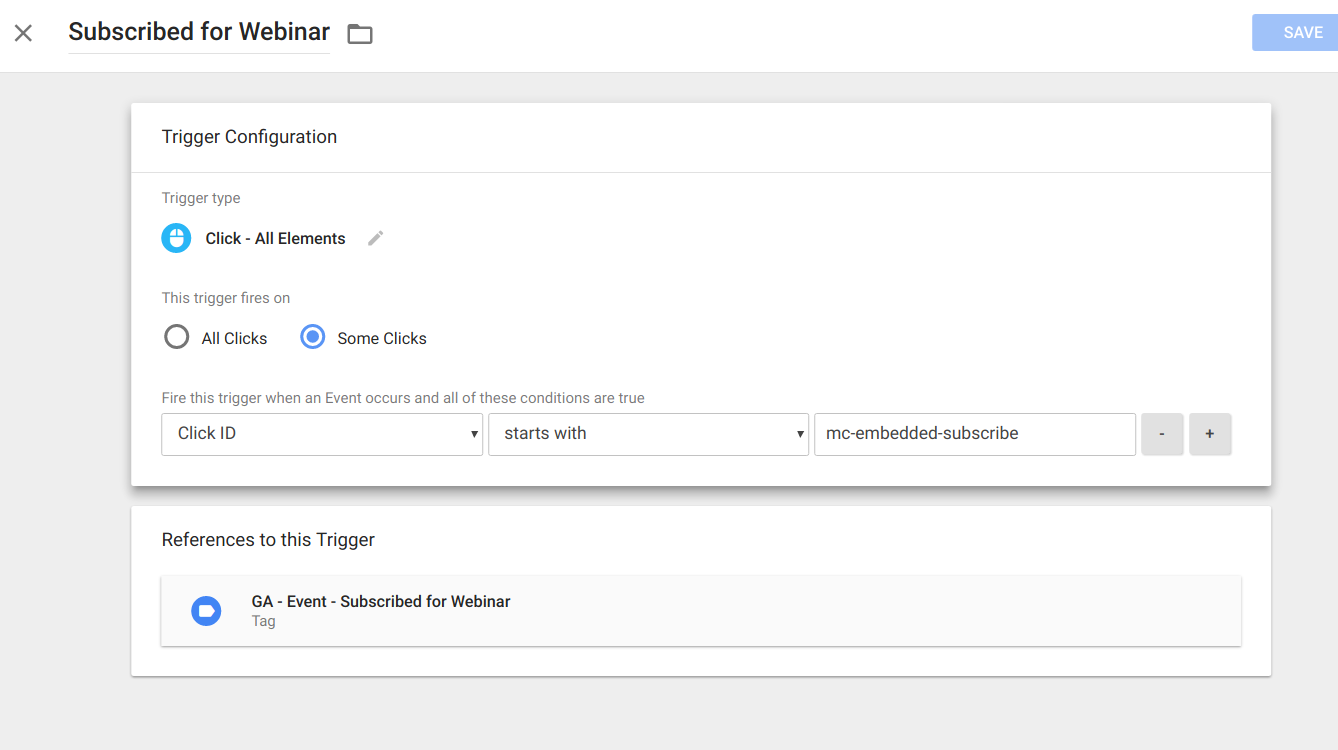
The screenshot below shows an event which we track on a landing page for when someone subscribes to a webinar.
@pigeonflight c.googleanalytics already integrates with the events api via javascript. The problem that can still only track clicks. If pdfs are loaded from a google search result or via a direct url, then this is not counted. It would need to happen server-side, not via JS.
Is it unreasonable to event track every link clicked? I think I've just hit the same issue, but in regards to tracking Link types which redirect externally.
@arterrey its not unreasonable but it misses direct links from google search results or external deep links. Also if JS turned off. Depending on the site, missing out on those stats could be significant or not.
At the moment we use log analysis but that also has its problems. Server-side GA would be the best solution as it could marry the users client side behaviour with downloads of non-html content.
@arterrey by metarefresh you mean you take control of the request to download, cause it to open html instead that has a JS GA tracking code in and then does a metarefresh to the download?
Not sure if this is helpful. We solved this problem for a client with Matomo (aka Piwik) and it wasn't too hard to accomplish. I am happy to look up how we did it if that is interesting for anybody...
Yes it would be good to know.
My solution using serverside GA has the problem that if strong caching is enabled for files then the hits aren't recorded. On the plus side it doesn't affect what happens when a user clicks download which unlike some of the redirect solutions suggested.
The solution we came up with seems to work well - https://github.com/collective/collective.googleanalytics/pull/41. Tracks downloads as virtual page views so you can see where users came from and went to, handles 304 not modified caching and filters crawlers and avoids any JS or theme conflicts. It also doesn't do any redirects or change how the browser downloads. It's likely to work with most plugins or custom code that provides downloads.
We will need the ability to track who has downloaded files and when on access restricted site, so Google Analytics isn't really a solution. I am considering having a single BrowserView that can access the file and having that view update annotations on the object with download info. This would cause a write on every download which may be a problem for a large public site, but for an area of the site that is restricted to a handful of authenticated users I would think it'd be fine.
The one thing I am worried about is if there is inadvertently left in some other browser endpoint that is capable of accessing the file object. For instance, if there was a BrowserView in some part of Plone core I am not aware of that simply calls self.context.file, I don't think that would even care about view permissions set on the zope.schema. One possibility is to have a new content type that does not call the field "file" just to reduce the chance of this happening. Is there a better way to force it so that there can't be other browser access points, or a better approach altogether?
GA works on intranets just fine. As long as there is internet access of the users browsers.
In fact even if users browsers don't have internet access this new plugin can still work. It sends the data from the server to google directly. So the server needs internet access.