Again, thanks so much for the effort here!! Super exciting!
I ran it with our stack, and the integration was flawless. It just worked.
Using `getTransferCounts`, I created a simple statistic to count the number of reads and writes in our test suite.
ZODB Loads: 372,323
ZODB stores: 414,717
I can see that the TCP latency to PG (compared to the in-memory ZODB) adds approximately 10%-15% to the runtime of the entire test suite. But that is expected and not an issue at all.
I’ll proceed and run the setup on our K8s cluster with a substantial amount of data.
ZODB's defining feature is transparent persistence - you read/write obj.foo (with foo a persistent object) and ZODB silently loads the object's state from storage via __getattribute__ / _p_activate(). In Python, you cannot await an attribute access. There's no__async_getattribute__. This means the single most important operation in ZODB (ghost -> loaded) is inherently synchronous.
A truly async ZODB would require rethinking the programming model - explicit loads instead of transparent activation - which sacrifices the very thing that makes ZODB elegant.
A connection pool of ZODB connections in dedicated threads, fronted by an async API, gives you async application code while keeping ZODB's proven internals intact. Pyramid + ZODB apps do this with gunicorn --worker-class uvicorn.workers.UvicornWorker . It works but it's async-around-ZODB, not native async ZODB.
As I do in many projects - and I wrote a whole addon stack for this purpose: collective.elastic.plone
But having both in your stack increases the maintenance effort.
My goal with plone-pgcatalog is to change this. PostgreSQL is well capable of replacing Elasticsearch. And if you don't want to be limited by the catalog's features, you can always build your own queries directly in SQL.
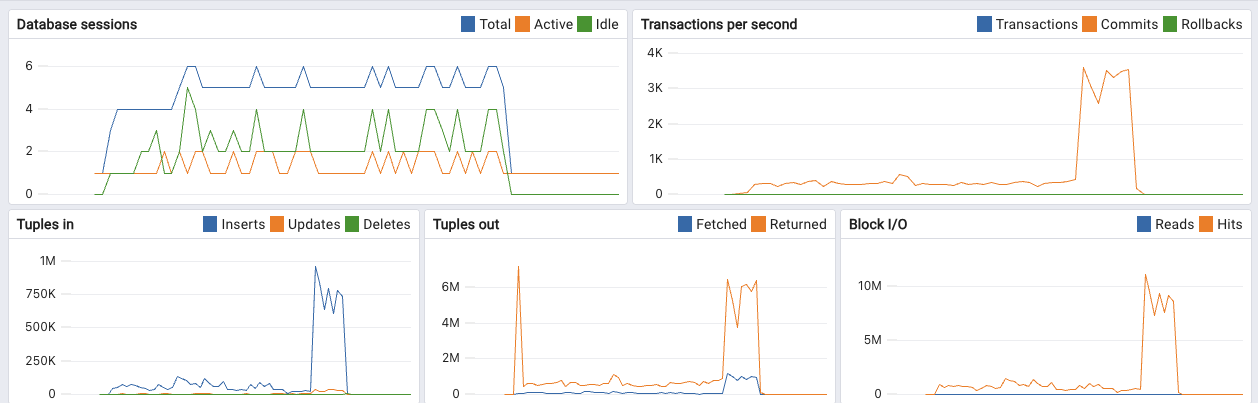
Looking at my first assessment and trying to implement plone-pgcatalog I realized I only applied my “DemoStorage bypass” patch to a subset of tests.
Hint: DemoStorage is entirely in-memory and was stacked on top of my PGLayer for most tests and is used to rollback the state after every test. To run true e2e tests in this case, you need to patch DemoStorage to route requests to the actual storage.
Well, after I figured that out. The overhead is a bit more, around 40%. Which again is not a Problem. I will go back to in-memory-db-testing eventually, but for now, I think it's a great way to test the integration of the new storage.
This being said. I got 2% failing tests and I’m investigating them right now. I cannot yet tell whether this is an issue with my test setup or with the storage itself.
Once that is resolved, I proceed with plone-pgcatalog.
Thanks for pointing out collective.elastic.plone.
Maybe you saw this: Collective.elasticsearch ES 8 support, AI and more - I’m not sure if I can just replace ES on my stack. We use many ES features, such as pipelines (data processing), vectors, and sophisticated query- and index-time boosting.
Thank you, @jensens! This project looks comparable to the effort of upgrading Plone to support python3: the next big step to modernize the stack. Kudos!
I have been doing some tests following the instructions at the plone-pgcatalog repo and the initial project setup (just using the zodb-pgjsonb package) works as expected in the initial setup.
Nevertheless, each time I run the pgacatalog install, the site breaks with different error messages.
Right now, we are working on a Plone 4 -> Plone 6 (Classic) migration, and today I decided to give a try with the project and migrate it to zodb-pgjosnb storage (without any S3 storage settting) and install also plone-pgcatalog.
First things first, without installing plone-pgcatalog, the site works OK. I have some issue with a content-type where I am saving external data in an annotation instead of regular fields, and I see that some data that are persisted in ZODB filestorage are not being persisted in the zodb-pgjsonb storage. The annotation has deep nested dict and list structures, and some lists are persisted but some dicts are not. I will double-check this, because I may be saving items in a wrong way...
In all other terms the site is working OK, the content views, edit forms, workflows, etc. are working OK and as expected.
Second, when I install plone-pgcatalog I start receiving TypeError: ('Could not adapt', <CatalogSearchResults len=0 actual=0>, <InterfaceClass plone.app.contentlisting.interfaces.IContentListing>) like errors. We are using Plone listings here and there, so we may need to add the corresponding adapter from CatalogSearchResults to IContentListing to make those listings work.
Those are my findings until this moment. I will keep doing some more tests and report them if I find anything else.
Thanks @jensens for updating cookiecutter-zope-instance.
Later today I will update cookiplone-templates to support this as an additional option for persistence.
Can you share what steps you had to do to run your tests with pgcatalog? I tested the catalog and storage in a pretty complex project and found no more problems but I’d love to check if all tests pass.
“The meat“: A postgres db layer, that patches the demo storage. pgjsonb_layer.py · GitHub Very much, super experimental. But that way, all my test cases are actually end-to-end tested.
Neither the ZODB nor the ZCatalog are well-designed components.
The ZODB has always been - a more or less - dumb pickle grave.
My understanding of a database is that you can store and query data.
That's why the ZCatalog has been dumped on top the ZODB for making data searchable. The separation of indexes is standard but the concept of brains and metadata is so rotten brain-dead...never ever seen something else in a real databases...beyond the fact that the capabilities of the ZCatalog have always been behind the options with a real-world databases...ok, Dieters AdvancedSomething...offered some relief but the architecture and - in particular - the implementation of the catalog.
Well, both lasted very long and served us well. However, this technology has been outdated very fast and both components should have been replaced in Zope and Plone within the first half of the first decade the new millennium.
Stretching. ZODB is done right. Its pragmatic and solved a problem of it's time. Python code is 90ies style. What to expect else?
ZCatalog. Well. It does its job, but should have been replaced by a sane index long time ago. Many years ago by Solr, in the last 5-10 years by ElasticSearch/Opensearch. But these days Postgresql features are more than sufficient for 99% of use cases.