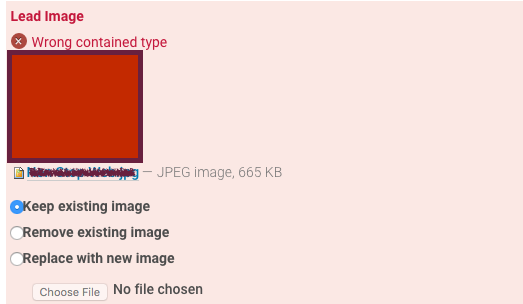
I generated json files from my source Plone site using collective.jsonify and then used a custom script to import my items (including News Items) into my Plone 5 site.
The content actually works and I can view the lead images associated with my News Items. Until I attempt to change a setting on the News Item (without changing the lead image itself) I get a "Wrong contained type" error... as if it can't save the existing lead image back to itself.
see screenshot:
For your reference I've included a snippet that demonstrates how I create my news items from the source json files.
from plone import api
from plone.app.textfield.value import RichTextValue
from plone.namedfile.file import NamedBlobImage
from base64 import b64decode
# the json file is loaded into a variable called "data"
def create_news_item(level, id, base_path, path_, name, data):
otherdata = {
"exclude_from_nav":True,
"contributors":data["contributors"],
"text":RichTextValue(data["text"]),
"allowDiscussion":data["allowDiscussion"],
"atrefs":data.get("_atrefs", {})
}
_path = "/".join(base_path.split('/')[:-1])
if level > 1:
container = api.content.get(path=_path)
else:
container = api.portal.get()
if container and id not in container:
obj = newsitem = api.content.create(
type='News Item',
title=name,
id=id,
safe_id=False,
container=container,
**otherdata)
obj.setLayout(data['_layout'])
obj.setExpirationDate(data['expirationDate'])
obj.setEffectiveDate(data['effectiveDate'])
obj.reindexObject()
setuid(obj, data['_uid'])
setImageData(obj, data)
setTransition(obj, data)
else:
print "content already present for {}".format(base_path)
def prep_image(imagename, data, content_type ):
""" load image from data string """
return NamedBlobImage(
data=b64decode(data),
contentType=content_type,
filename=imagename)
Thank you very much @1letter. Based on your suggestion I was able to get it to work. I looked more carefully at my code and "imagename" IS definitely unicode therefore "filename" will be unicode as it should be.
So I changed my code to explicitly set the "content_type" value to a string.
It also suggests that I don't need to specify the content type (mimetype), so I probably could have skipped setting the content type and let the code detect it. My "prep_image" method now looks like this:
def prep_image(imagename, data, content_type ):
""" load image from data string """
return NamedBlobImage(
data=b64decode(data),
# SET THIS TO BE A STRING
contentType=str(content_type),
filename=unicode(imagename))
Note that I force contentType to be set as a string. It now works.
Even though I'm confident that all my incoming values are unicode, to be doubly sure, I also changed the last line of prep_image to explicitly set the filename to unicode.
@rodfersou
Actually, I don't think so. As I understand the case, the attribute will just corrected on the fly - e.g. on next edit or scaling.
However, your PR fixes the situation and there shouldn't be any regressions, even if we need an upgrade step.
Let me know, if you encounter problems and think that an upgrade step is necessary.