We have been using ZRS for a while but we still have the problem of a single point of failure on the blob storage. In the past I read about GlusterFS but many people said it had issues with small files and complex directory structures... just our use case.
So we decided to give a try: installation was smooth under Ubuntu 14.04 and I was able to mount a volume distributed in 2 Digital Ocean droplets following a couple of howtos.
Problems started when I decided to test a real environment: I created the volume and configured it and when I started copying the blob storage inside it, weird things started to happen.
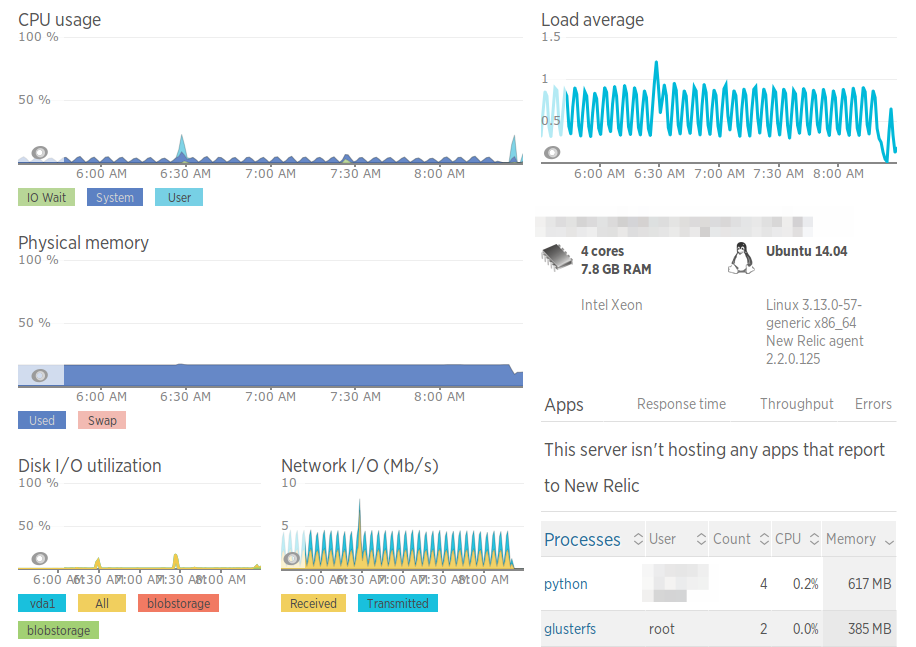
First the second server became somehow unresponsive: some commands did not run like a single df -h. I restarted the machine and returned after a few hours, then I saw the CPU usage was on some sort of oscillation.
When I started my stack (nginx, Varnish, ZRS server and 4 Plone instances), I found that I was not able to reach Varnish on port 6081, neither the Plone instances on ports 8081-8084. I had to stop the GlusterFS volume to being able to reach them but seems ngnix is still unable to reach Varnish and I'm getting a lot of timeout errors on the log.
This test was not on the biggest site we're running so I guess either my configuration has problems or simply GlusterFS is not the right tool for this job:
$ sudo gluster volume info
Volume Name: blobstorage
Type: Replicate
Volume ID: 12345da2-40fc-4c61-a53e-123456e4dd96
Status: Stopped
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: server1:/var/blobstorage
Brick2: server2:/var/blobstorage
Options Reconfigured:
diagnostics.brick-log-level: WARNING
diagnostics.client-log-level: WARNING
nfs.enable-ino32: on
nfs.addr-namelookup: off
nfs.disable: on
performance.cache-max-file-size: 2MB
performance.cache-refresh-timeout: 4
performance.cache-size: 256MB
performance.io-thread-count: 32
performance.write-behind-window-size: 4MB
I've been looking for alternatives and I read about using NFS with DRBD and Pacemaker but I'm not very enthusiastic because of the complexity on having to add 2 new technologies to our current stack.
What are you guys using nowadays to deploy HA sites with Plone?
We are using DRBD for both, ZODB and NFS on a machine with a failover address.
The whole is OpenAIS based and uses Pacemaker as cluster resource manager and Corosync as Cluster Engine.
Also the chain NGINX, Varnish, HA-Proxy runs redundant on two machines using this technology.
Initially it is indeed a complex topic, but once you got it its worth every minute you struggled with it. Afterwards you'll have a real good and robust setup.
It replaces any systemd-supervisor-init script system to start the services (it uses itself OFS scripts, kind of similar to init scripts but with more complex status reporting).
@hvelarde@djay I also tried here with GlusterFs, but, the CPU to be idle, lots of memory to be available, no swapping, no I/O, but a high average load.
One more question, @djay@pbauer, do you have instances running on the ZRS slave?
In such case, how do you configure to allow them to be used by editors? do you set shared-blob = off? If so, what happens to the blobs on the instances?
We use a huge zeo-client-cache-size but I don't know if all the blobs are also copied to the blob-storage location or only those that are alive in the ZODB cache.
seems that "somebody" had changed the firewall rules on teh server blocking some ports on the private interface and that was messing around with Varnish and, probably, with GlusterFS; those rules were applied when I restarted the VM. so, part of the mystery is now solved.